The project that has been 90% done for six months. The program that is 5 years late. The company division that continually loses money, but somehow, survives, getting more good money thrown after bad. The larger the company you work for, the more likely you have seen this phenomena in action.
My term for this is a concept called Egospend. Egospend is what happens when you combine:
- a large sum of financial and/or political capital
- little or no discipline around relevant business metrics, measured frequently
- a culture with a strong sense of loss aversion / high penalties for perceived failure
- decision making by feel and relationship versus results
The degree of Egospend in an organization tends to be the product of those four factors.
Why Traditional PMOs Are Ineffective Against Egospend
Most organizations recognize and want to combat Egospend. Combating Egospend is one of the reasons PMOs came to be, as well as various other forms of governance that occur at various levels of an enterprise. Intentions are always quite good, as nobody enjoys taking multi-million dollar writeoffs after failed projects.
What occurs, unfortunately, as it does in all political systems, is some form of regulatory capture. On the X axis, we have political support for an idea…. let’s call this CSAPS, “Combined Salaries of All Project Sponsors”. On the Y axis, we have HCI, “Historical Costs of Initiative”.
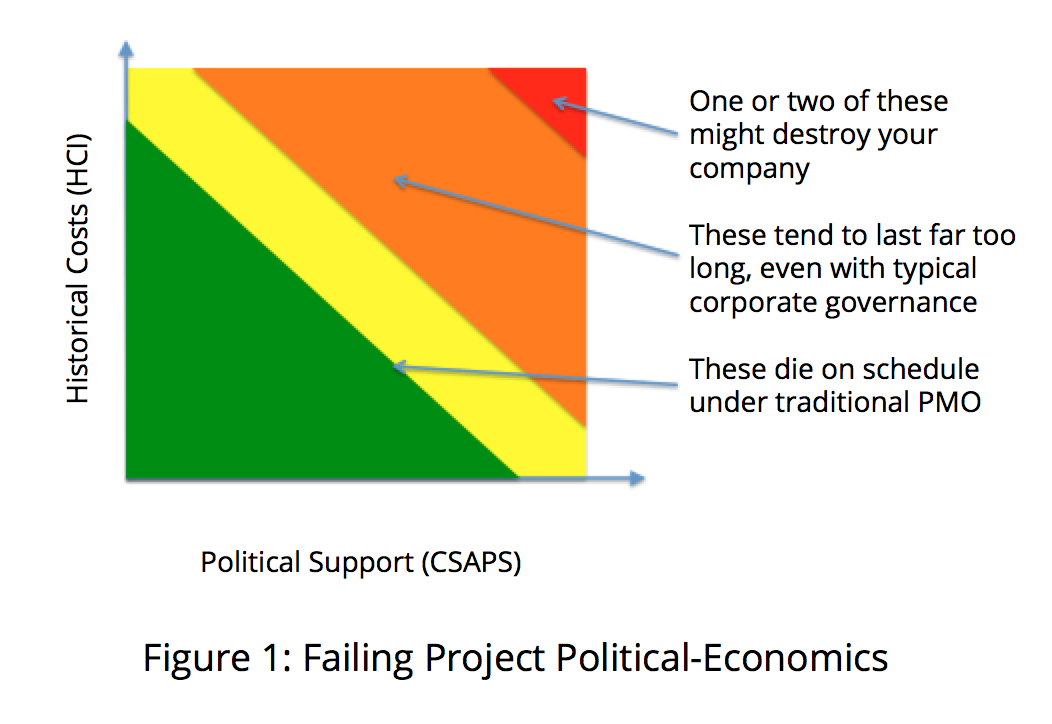
What does “regulatory capture” mean in this context? It admits to the reality that political power can defeat governance functions. In nearly all companies, if the CEO decides to continue funding an initiative that should have died, it will continue to get funding, despite the opinions of the PMO. This is true for traditional PMOs, Lean PMOs, or any other kind that exists in any structure where political power is centralized, such as nearly all modern enterprises.
This effect, of course, is accelerated under corporate cultures that are prone to loss aversion. All it takes are a few executives who have had careers ended over high profile failures – something that isn’t atypical – in order to lock loss aversion into the corporate culture for a very long time.
Where Traditional PMOs Go Wrong
The issue with traditional PMO isn’t the intent. They are often very good at making sure projects are delivered (of course, this isn’t always true either). The issue is deeper – do the projects achieve the business results they were designed to achieve. A key tenent of the Lean Startup movement is that you don’t claim done upon product creation. Rather, you orient around building a product or service where you create a virtuous learning cycle. A learning cycle that works in a manner where you end up with a product that delivers continuous improvement of business results.
Where does this differ from traditional PMOs? Most PMOs try to control change (see, Change Control Board), where Lean PMOs expressly enable and expect change. Successful outcome for a traditional PMO is project delivery, successful outcome for a Lean PMO is results delivery. Traditional PMOs expect projects to finish and move into “maintenance”, Lean PMOs expect products to continually evolve and pivot in order to meet new and evolving customer needs.
By focusing on delivery of projects, with the key metric being project completeness and delivery status, i.e. “did we deliver software – regardless of whether it is the software that a customer actually wants”, the Traditional PMO is blind to actual business results.
Combating This with Lean Enterprise
The idea of Lean Enterprise is to take the lessons from Lean Startup and apply them to the enterprise. How do you take the discipline a startup must have to survive – laser focus on customers, early feedback, real, non-vanity metrics, obsessive focus on your product – and make that work in multi-billion dollar organizations? Surely, there are adaptations – there are regulatory constraints, audit committees, and sheer size that changes how you approach the problem. There are also technical constraints – protection of data is a much bigger deal for a financial services behemoth than it is, say, for a social media startup. You can’t just walk into a Fortune 50 company with Lean Startup as your playbook and be successful.
However, in order to avoid the projects that have both high CSAPS and HCI – the kinds of projects that kill companies, something has to be done. Since CEOs will continue to have ideas, the only real way to combat the perils of Egospend is to lower HCI for initiatives that are doomed to failure. Failure defined by poor business results, not just mere poor project delivery.
How do you do this? We start with Continuous Delivery – the idea that instead of delivering things in large chunks, you deliver incrementally, so you can measure what each change does. You deliver an MVP early, so you can start to get feedback as soon as possible and know whether you need to pivot. You change the way funding works, moving away from annual budgets with fixed scope, and towards contingent budgets based on meeting business objectives.
As you evolve, you start to build a culture that embraces early failure – and learning from same as part of the path towards success. At some point, even the CEO becomes someone who can admit, in a company-wide meeting, that his or her pet idea did not work. By setting such an example, the organization becomes one where hubris and bravado are seen as negative traits, not forms of faux leadership.
Enterprises Need Lean More Than Startups
The irony, of course, is it is the large enterprises of the world that need these ideas the most, since they tend to be where most of the large amounts of money are spent on technology. I have personally seen initiatives in single companies, doomed to failure, that ate up budgets equal to the entire GDP of a developing world country. Initiatives for whom admitting failure would mean the CEO would lose his job (and, thus, more continued investment). Imagine the capital that could be put to better use if we could put an end to this kind of wasteful Egospend.
If you are interested in reading more about this, you can get four chapters of the book, Lean Enterprise, for free, authored by my colleagues Barry O’Reilly and Joanne Molesky, as well as ThoughtWorks Alum Jez Humble.